
Python Music Recommender: A Practical Guide Part-2
Creating a Music Recommendation Engine in Python: A Practical Tutorial


In my previous blog, you learned about Spotify API and how we could use it to analyze any playlist. So now let's learn how you can build a music recommendation system using the Spotify music dataset using Python, and machine learning.
Music recommendation systems are currently a popular type of recommendation system that is used to suggest songs or playlists to users based on either listening history or certain preferences.
Spotify is among the popular music streaming platforms. It contains a vast amount of data that can be utilized to build a recommendation system.
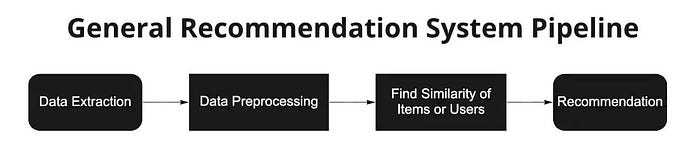
What’s the problem?
Before building a music recommendation system, you should understand the problem you aim to solve. In this case, I want to recommend songs that are contained in a playlist dataset.
Collecting Data
Spotify has a web API that can be used to access information about a playlist on Spotify.
Here’s the link to my previous article where I discussed in detail how to get playlist data using Spotify API
Data Preprocessing
After the data has been collected, you need to preprocess it so that it would be usable for our model.
The preprocessing includes cleaning the data, checking for missing values and creating features based on the song tempo, loudness etc.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.manifold import TSNE
import warnings
warnings.filterwarnings('ignore')
# Reading the file that was extrated by 'playlist_analysis.py'
tracks = pd.read_csv("playlist_features.csv")
tracks.head(3)
Output:

# Checking for null values in the dataset
tracks.isnull().sum()
Output:

Data Exploration (Exploratory Data Analysis)
It’s good to perform EDA, this helps to understand the data better and gain meaningful insights.
Various Python libraries such as pandas, numpy, and seaborn can be used for EDA.
I have already done it in my previous blog. So let's start building the model.
Building The Model
After having the data preprocessed and understood, you can start building the model.
There are several algorithms available for building recommendation systems, including collaborative filtering, content-based filtering, and hybrid systems.
Popular libraries such as scikit-learn and surprise can be used to implement these algorithms.
I used the CountVectorizer to build a model based on the Popularity column feature.
# Using CountVectorizer to build a model
song_vectorizer = CountVectorizer()
song_vectorizer.fit(tracks["Name"])
# Sorting by Popularity
tracks = tracks.sort_values(by = ["Popularity"], ascending = False)
tracks.head()
The songs were sorted by their Popularity
Output:

Creating a similarities function using Cosine Similarity
def get_similarities(song_name, data):
text_array1 = song_vectorizer.transform(data[data["Name"] == song_name]["Artist"]).toarray()
num_array1 = data[data["Name"] == song_name].select_dtypes(include = np.number).to_numpy()
sim = []
for idx, row in data.iterrows():
name = row["Name"]
text_array2 = song_vectorizer.transform(data[data["Name"] == name]["Artist"]).toarray()
num_array2 = data[data["Name"] == name].select_dtypes(include = np.number).to_numpy()
text_sim = cosine_similarity(text_array1, text_array2)[0][0]
num_sim = cosine_similarity(num_array1,num_array2)[0][0]
sim.append(text_sim + num_sim)
return sim
def recommend_songs(song_name, data = tracks):
if tracks[tracks["Name"] == song_name].shape[0] == 0:
print ("This song is either not so poplular have entered an invalid name not contained in this playlist")
for song in data.sample(n=7)["Name"].values:
print(song)
return
data["similarity_factor"] = get_similarities(song_name, data)
data.sort_values(by = ["similarity_factor", "Popularity"],
ascending = [False,False], inplace = True)
display(data[["Name", "Artist"]][1:7])
recommend_songs ('Kesariya (From "Brahmastra")')
The result after inputting the name of a song contained in the dataset is:

These songs were recommended based on their popularity and similarity with the song inputted.
Conclusion
Building a music recommendation system using Python, machine learning, and Spotify dataset might be a complex task (I experienced pains dealing with bugs). With the right tools and techniques, it is possible to create a powerful system that can provide personalized recommendations to users.
In this article, I discussed the basics of building a music recommendation system using the Spotify dataset, including data collection, preprocessing, and model building.
With the help of Python libraries and machine learning algorithms, we can build a robust and efficient music recommendation system, a movie recommendation system, a book recommendation system etc.
Machine Learning and Python are amazing
Until then take care, Happy Learning!
Thanks for Reading!